本文最后更新于517 天前,其中的信息可能已经过时,如有错误请发送邮件到takumijie@qq.com
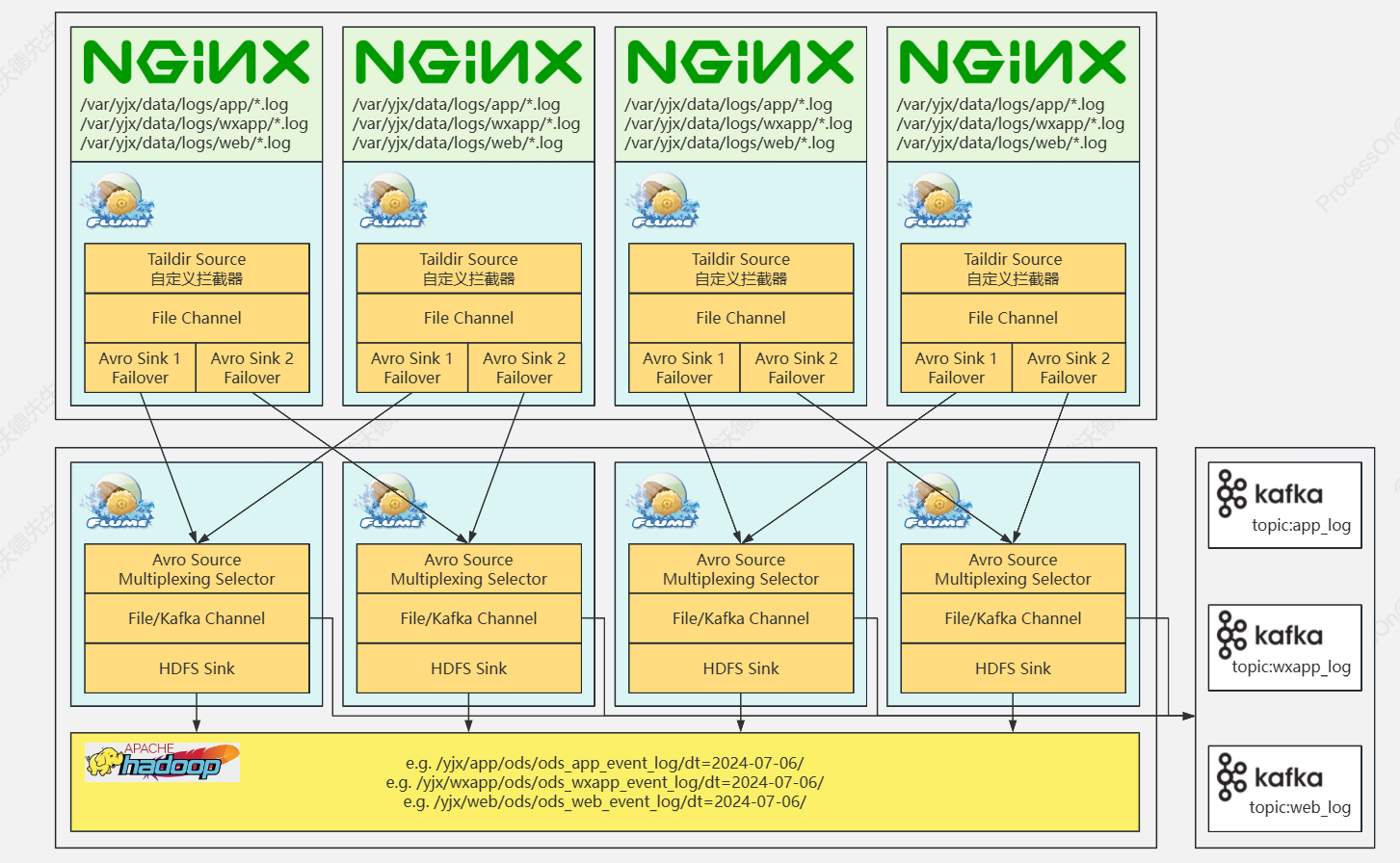
行为数据采集架构
1. 数据埋点
- 使用第三方sdk进行埋点数据的采集(泛埋点不够精准);
- 在前端进行数据埋点,使用OpenResty:Nginx将用户行为存储到日志服务器(image beacon);
- 在后端通过代码进行埋点(访问接口传回数据)
2.外网端设计
- 使用了四台服务器进行数据的采集
- 使用了taildir source(支持断点续传)
- 使用了自定义拦截器(用于给不同端的数据打上标记)(解决0点漂移问题[使用事物时间戳])
- 使用 avro source/sink 适用于大规模数据的处理(二进制传输)
- 每台服务器配置两个sink(故障转移,防止某台服务器的sink宕机导致数据采集不全)
3.内网端设计
- 内网端使用了avro source(配置了多路复用用于将外网端标记的数据进行分流处理【wechat/web/app】)
- 分流后数据通过kafa,channel直接进入不同主题的kafka
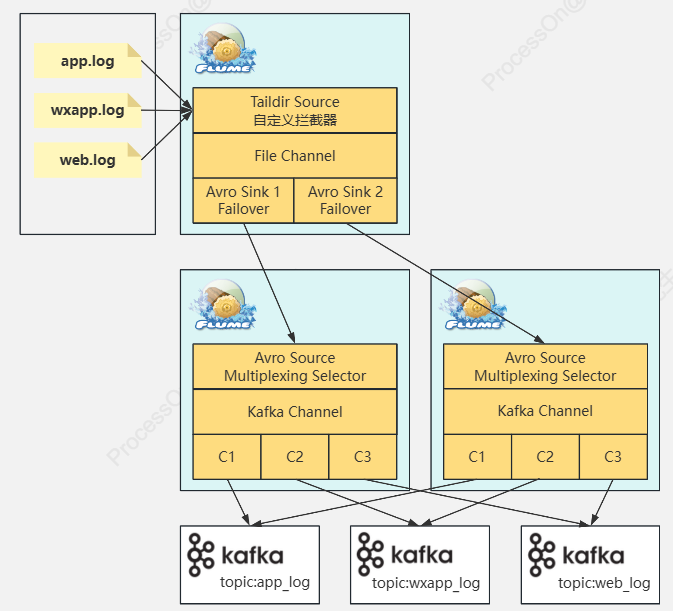
- 分流后的数据也通过hdfs sink写入hive(hive与hdfs都是使用hdfs sink)
4. flume的优化
- 如果使用SpoolDir Source或者Exec Source可以通过修改
batchSize和spoolInterval参数来修改读取的频率和每次读取的事件次数
# Exec Source 配置示例agent.sources.exec-source.type = execagent.sources.exec-source.command = tail -f /var/log/messagesagent.sources.exec-source.batchSize = 100 # 每次从命令输出中读取 100 条事件agent.sources.exec-source.pollInterval = 1000 # 每隔 1000 毫秒读取一次数据# SpoolDir Source 配置示例agent.sources.spool-source.type = spooldiragent.sources.spool-source.spoolDir = /tmp/logsagent.sources.spool-source.batchSize = 50 # 每次批量读取 50 个文件agent.sources.spool-source.spoolInterval = 1000 # 每隔 1 秒扫描一次目录
- 修改channel的容量以及批量大小
# Memory Channel 配置示例agent.channels.memory-channel.type = memoryagent.channels.memory-channel.capacity = 10000 # 最大容量,控制 Channel 中存储事件的数量agent.channels.memory-channel.transactionCapacity = 1000 # 每次事务的容量,控制一次事务处理的事件数
- 修改jvm的参数内存大小
- 通过调整 Sink 的批量大小、滚动时间和事件数量,可以控制 Sink 处理事件的速率和频率
# HDFS Sink 配置示例agent.sinks.hdfs-sink.type = hdfsagent.sinks.hdfs-sink.channel = memory-channelagent.sinks.hdfs-sink.hdfs.path = hdfs://namenode/flume/data/agent.sinks.hdfs-sink.hdfs.rollSize = 10485760 # 每个文件的最大大小为 10MBagent.sinks.hdfs-sink.hdfs.rollInterval = 3600 # 每小时滚动一次文件agent.sinks.hdfs-sink.hdfs.rollCount = 10000 # 每 10000 条事件后滚动一次文件# Kafka Sink 配置示例agent.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSinkagent.sinks.kafka-sink.channel = memory-channelagent.sinks.kafka-sink.batchSize = 100 # 每批次发送 100 个事件



