Hadoop MapReduce

1.简介
- MapReduce 是一种用来处理大量数据的工具
- Map(映射):先把数据分成小块,然后每块数据都交给一个“工人”(即 Map 函数)去处理,每个工人只处理自己那一小块。
- Reduce(归约):当所有工人都数完自己的数据后,系统会把相同的单词汇总到一起,比如所有关于“苹果”的结果放在一起,所有“香蕉”的结果放在一起。
- 总结一下,MapReduce 其实就是先分块处理,再汇总结果。这样,我们就能快速处理很大的数据集,因为每个工人只需要管自己那一小块,处理速度很快!
2.常用排序算法
MapReduce常用快速排序和归并排序
1.快排——左右指针法

- 左右指针法算法步骤:定义一个 Begin 指向第一个元素,定义一个 End 指向最后一个元素。令第一个元素为 Key,Begin 向后找大于 Key的值,End 向前找小于 Key 的值,找到之后把 Begin 跟 End 位置的值交换,直到 Begin 的索引大于等于 End 的索引时结束,然后将 Key 和End 指针值交换。再将 Key 的左右两边重复上述操作,最终有序。
2.快排——挖坑法
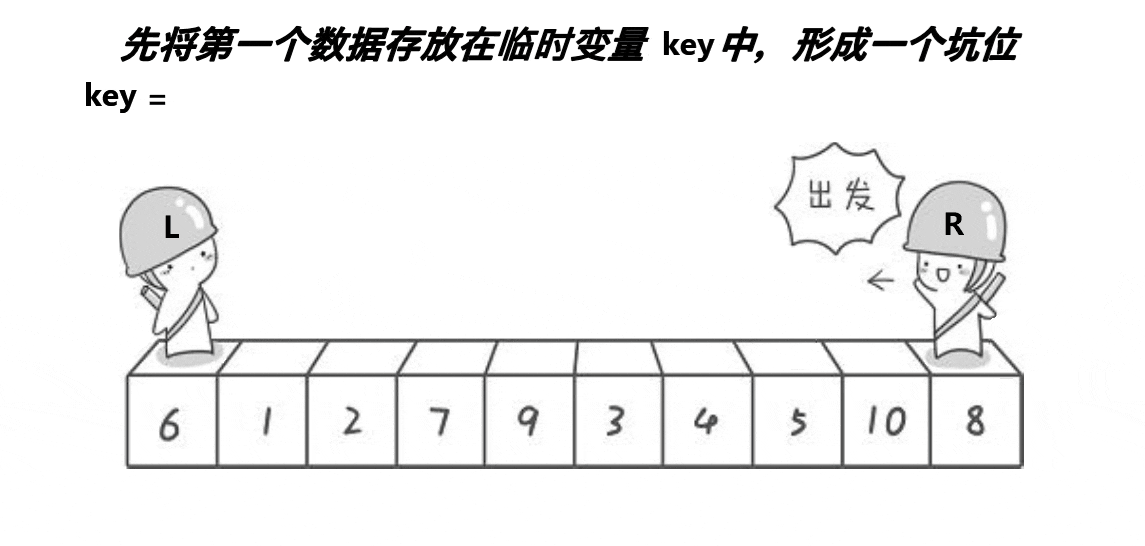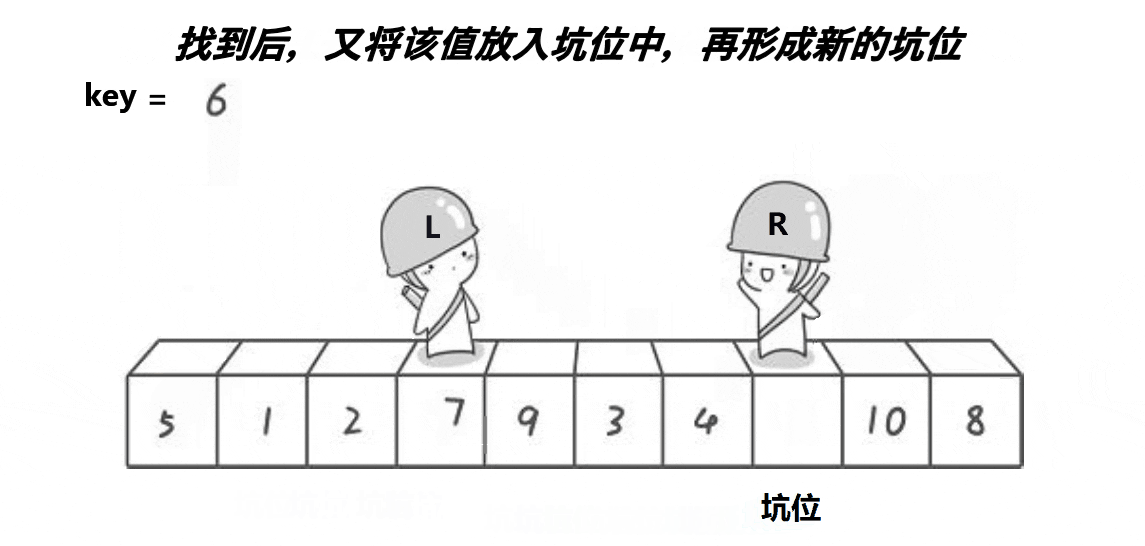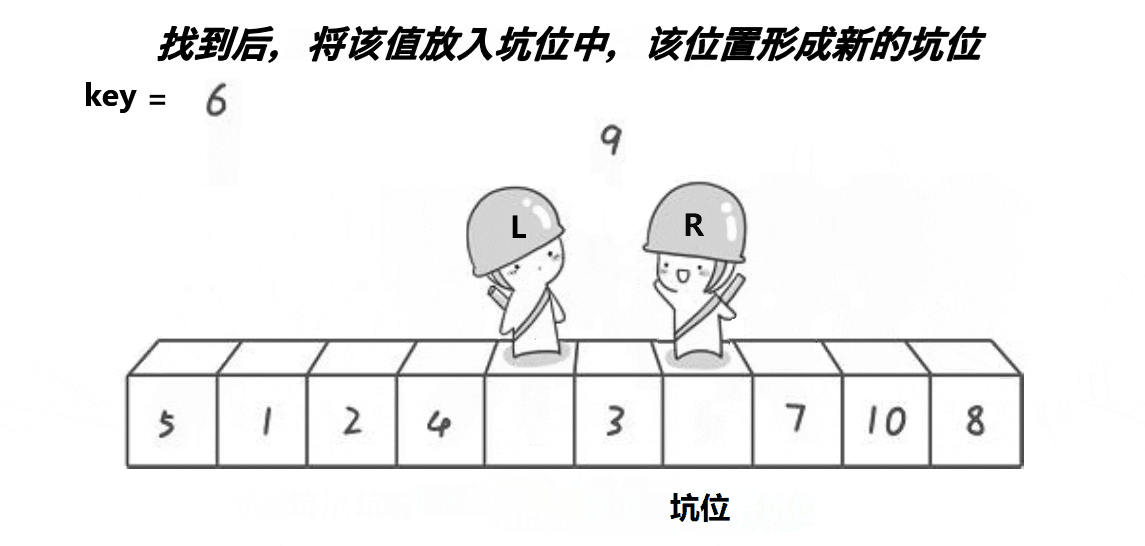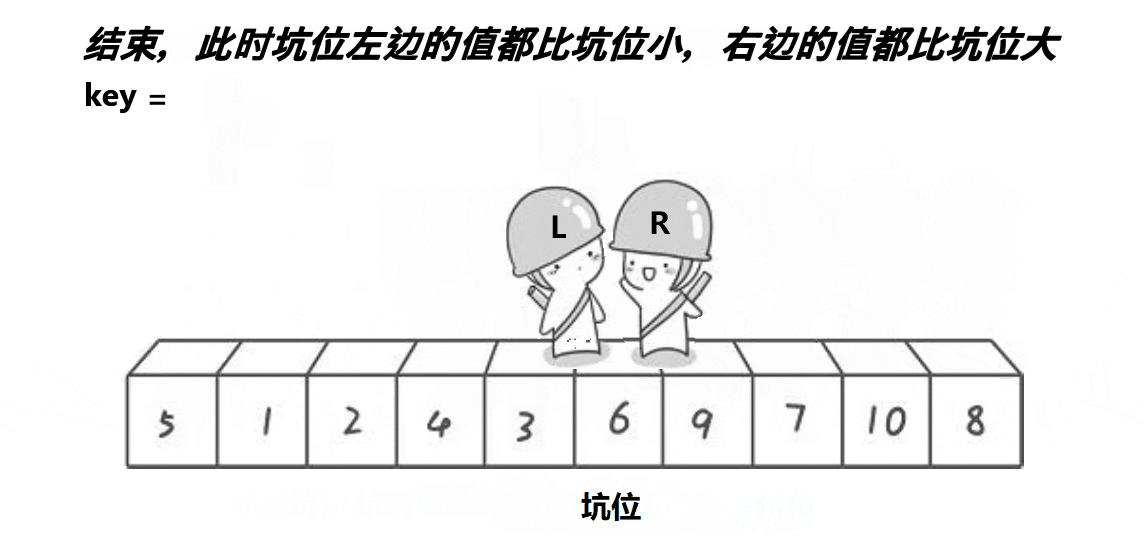
以 arr = [6, 1, 2, 7, 9, 3, 4, 5, 10, 8] 为例,以下是详细步骤:
- 选择基准
选取第一个元素6作为基准。 - 第一轮排序(从右向左)
基准在最左边,从右向左依次和基准比较:- 从右边开始,依次找到小于基准的数
5,将其与基准6交换。 - 结果为
arr = [5, 1, 2, 7, 9, 3, 4, 6, 10, 8]。
- 从右边开始,依次找到小于基准的数
- –第二轮排序(从左向右)
基准此时在右边,从左向右依次和基准比较:- 从左边开始,依次找到大于基准的数
7,将其与基准6交换。 - 结果为
arr = [5, 1, 2, 6, 9, 3, 4, 7, 10, 8]。
- 从左边开始,依次找到大于基准的数
- 第三轮排序(从右向左)
基准此时在左边,从右向左依次和基准比较:- 从右边开始,找到小于基准的数
4,将其与基准6交换。 - 结果为
arr = [5, 1, 2, 4, 9, 3, 6, 7, 10, 8]。
- 从右边开始,找到小于基准的数
- 第四轮排序(从左向右)
基准此时在右边,从左向右依次和基准比较:- 从左边开始,依次找到大于基准的数
9,将其与基准6交换。 - 结果为
arr = [5, 1, 2, 4, 3, 6, 9, 7, 10, 8]。
- 从左边开始,依次找到大于基准的数
- 基准位置确定
此时基准6已在正确位置,左边为[5, 1, 2, 4, 3],右边为[9, 7, 10, 8]。 - 左右递归排序
将左右两部分当作新的子数组分别进行排序:- 左边部分
[5, 1, 2, 4, 3]选择5作为基准,经过多次排序得到[1, 2, 3, 4, 5]。 - 右边部分
[9, 7, 10, 8]选择9作为基准,经过多次排序得到[7, 8, 9, 10]。
- 左边部分
- 合并结果
- 最终排序结果为:
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]。
3.快排——优化选key
在快速排序中,理想情况下,每次选到的基准值(Key)都是当前序列的中间值,这样效率最高。然而,在未优化的快速排序中,如果待排序数组是有序的,选 Key 总是选择最左边或最右边的元素,导致效率大幅下降。在这种情况下,快速排序的时间复杂度会达到最差的情况。
例如,给定 arr = [1, 2, 3, 4, 5, 6, 7, 8],基准为 1:
-
第一轮:基准
1位于最左边,从右向左依次与基准比较:- 所有元素都比基准大,保持不变。此时
arr = [1, 2, 3, 4, 5, 6, 7, 8],共比较了7次。
- 所有元素都比基准大,保持不变。此时
-
第二轮:基准移动到第二位,变成
2,从右向左依次与基准比较:- 所有元素都比基准大,保持不变。此时
arr = [1, 2, 3, 4, 5, 6, 7, 8],共比较了6次。
- 所有元素都比基准大,保持不变。此时
-
第三轮:基准移动到第三位,变成
3,从右向左依次与基准比较:- 所有元素都比基准大,保持不变。此时
arr = [1, 2, 3, 4, 5, 6, 7, 8],共比较了5次。
- 所有元素都比基准大,保持不变。此时
以此类推,直到排序完成,总共进行了 7 + 6 + 5 + ... + 1 = 28 次比较。
为解决这一情况,可以使用“三数取中”的方法来优化。
“三数取中”是指在数组中选择首、中、尾三个数中既不是最大也不是最小的数作为基准值。通过排序这三个数来得到中间值,将其作为基准,避免了总是选择最左或最右的极端情况。
三数取中示例
假设 arr = [1, 2, 3, 4, 5, 6, 7, 8]:
- 三数取中得到首(
1)、中(5)、尾(8)的中间值5,将5作为基准。 - 交换基准和首元素,得到:
arr = [5, 2, 3, 4, 1, 6, 7, 8]。
-
第一轮排序(从右向左)
基准5在最左边,从右向左依次和基准比较:- 找到
1,与基准交换。结果为arr = [1, 2, 3, 4, 5, 6, 7, 8],共比较了4次。
- 找到
-
第二轮排序(从左向右)
基准5在右边,从左向右依次和基准比较:- 找到
6,与基准交换。结果仍为arr = [1, 2, 3, 4, 5, 6, 7, 8],共比较了4次。
此时基准位置已正确,左右无序。
- 找到
-
左右递归排序
将左右两边分别视为新数组,继续挑选基准元素:-
左边部分
[1, 2, 3, 4],基准为3:- 经过多次比较后,得到
[1, 2, 3, 4],共比较了4次。
- 经过多次比较后,得到
-
右边部分
[6, 7, 8],基准为7:- 经过多次比较后,得到
[6, 7, 8],共比较了2次。
- 经过多次比较后,得到
-
经过“三数取中”优化后,比较次数减少至 4 + 4 + 4 + 2 = 14 次,比未优化前的 28 次少了许多。
其他 Key 选择优化方法
- 随机选 Key:随机选择基准值,减少最差情况的概率。
- 选中间值:对于已知有序的数组,直接选择中间值为基准。
4.归并排序

归并排序算法步骤:
- 将原序列二等分,二等分之后的子序列继续二等分;
- 直到每个子序列只有一个元素时,停止拆分;
- 再按照分割的顺序进行归并。

3.MapReduce计算流程
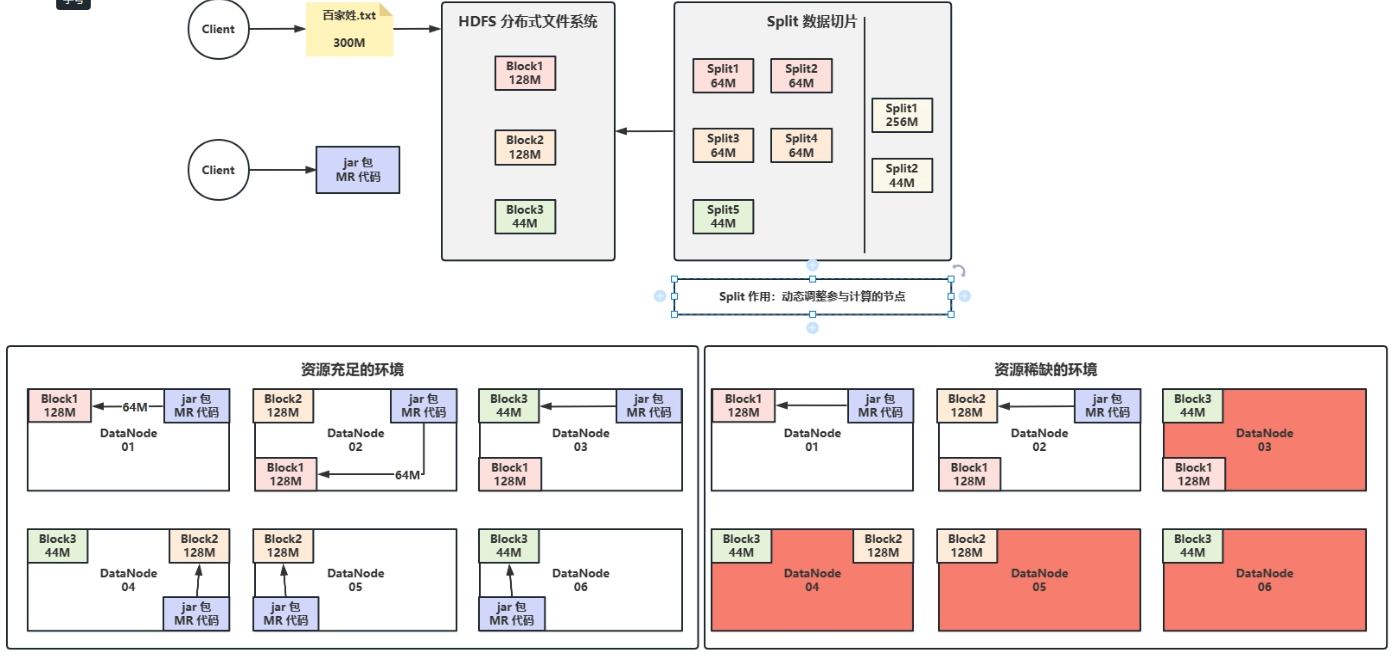
1.Split(分片)
- 原始数据先上传到HDFS进行分块处理。
- 在MapReduce的设计思想中计算要向数据靠拢,所以数据的计算应该在数据节点上去完成,编写完的程序直接上传到数据节点,并对其中的数据进行计算。
- 因为数据存储到HDFS上不可变,可能导致节点性能和块的数量不匹配。
- 所以需要动态的调整。
- 便有了切片处理,不改变现有数据的存储的情况下,控制参与计算的节点的数量
- Split默认为128M
- 一般切片大小为Block的整数倍(2 1/2)
- 如果Split>Block ,计算节点少了
- 如果Split<Block ,计算节点多了
2.MapTask
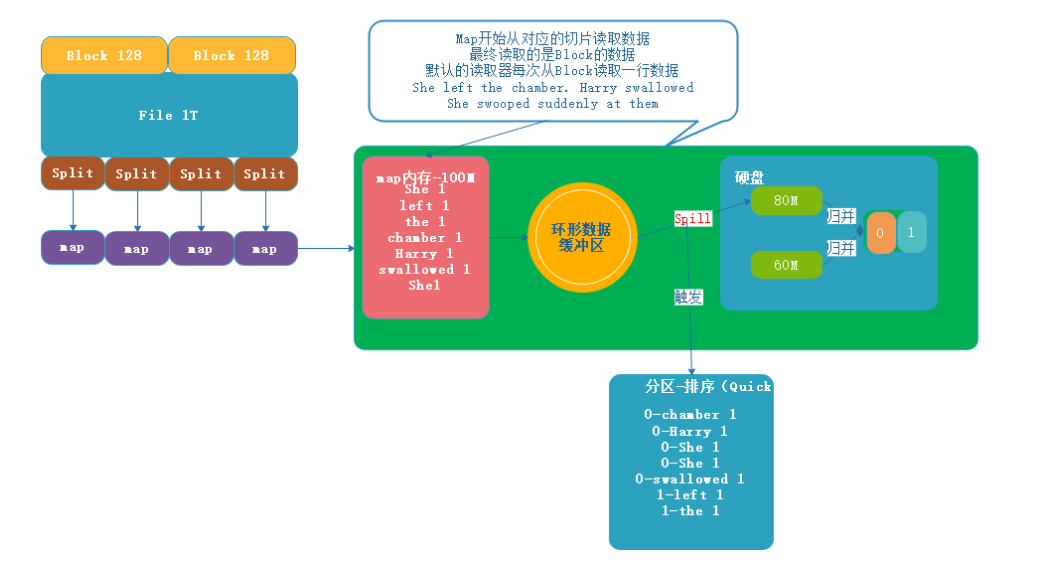
- 一个Split会对应一个MapTask。
- map默认从所属切片读取数据,每次读取一行(默认读取器)到内存中
- 我们可以根据自己书写的分词逻辑(空格分隔).计算每个单词出现的次数
- 这时就会产生 (Map<String,Integer>)临时数据,存放在内存中
- 但是内存大小是有限的,如果多个任务同时执行有可能内存溢出(OOM)
- 如果把数据都直接存放到硬盘,效率太低
- 我们需要在OOM和效率低之间提供一个有效方案(可以先在内存中写入一部分,然后写出到硬盘)
3.环形数据缓冲区
- 环形数据缓冲区默认100M
- 每一个Map可以独享的一个内存区域
- 如果按照写满环形数据缓冲区再重新读取会导致卡顿(因为要先写出)。
- 所以只能写到80%开始溢写到磁盘
- 溢写的时候还有20M的空间可以被使用效率并不会被减缓
- 而且将数据循环写到硬盘,不用担心OOM问题
- 剩余的20%内存会写入元数据(数据偏移量,分区,排序信息)

4.分区&排序
- 将数据读取到环形数据缓冲区中的时候会立即执行程序员自定义的代码(自定义重写的map函数)
- 对缓冲区中的数据进行排序,按键排序将相同的键值对排在一起。
- 默认情况下,MapReduce 使用键的哈希值来进行分区。
- 这样可以确保相同的键被分配到相同的分区,从而被同一个 ReduceTask 处理。
5.合并Merge
- 因为溢写会产生很多有序(分区 key)的小文件,而且小文件的数目不确定
- 后面向reduce传递数据带来很大的问题(太多的网络io可能造成数据丢失)
- 所以将小文件合并成一个大文件,将来拉取的数据直接从大文件拉取即可
- 并小文件的时候同样进行排序(归并排序),最终产生一个有序的大文件
- Merge 是为了让传输的文件数量变少,但是网络传输数据量并没有改变,只是减少了网络 IO 次数
- 默认10个合并为一个按照分区合并。
6.组合器(可选组件)
- 实现MapTask的预聚合
- 可以减少数据的传输量
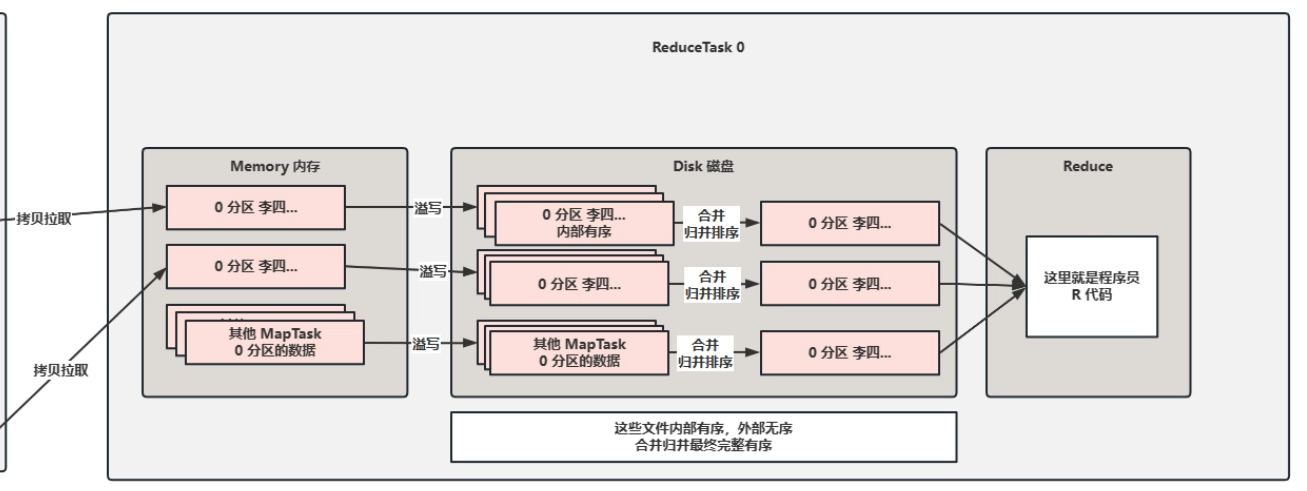
7.拉取Fetch&归并
-
MapTask处理完之后会被ReduceTask拉取处理完的数据
-
在ReduceTask拉取完之后也会进行排序(归并排序因为MapTask处理之后是内部有序外部无序)
-
这里的合并也是默认10个合并一个
-
也有一个相同的环形数据缓冲区,不过不用再记录元数据
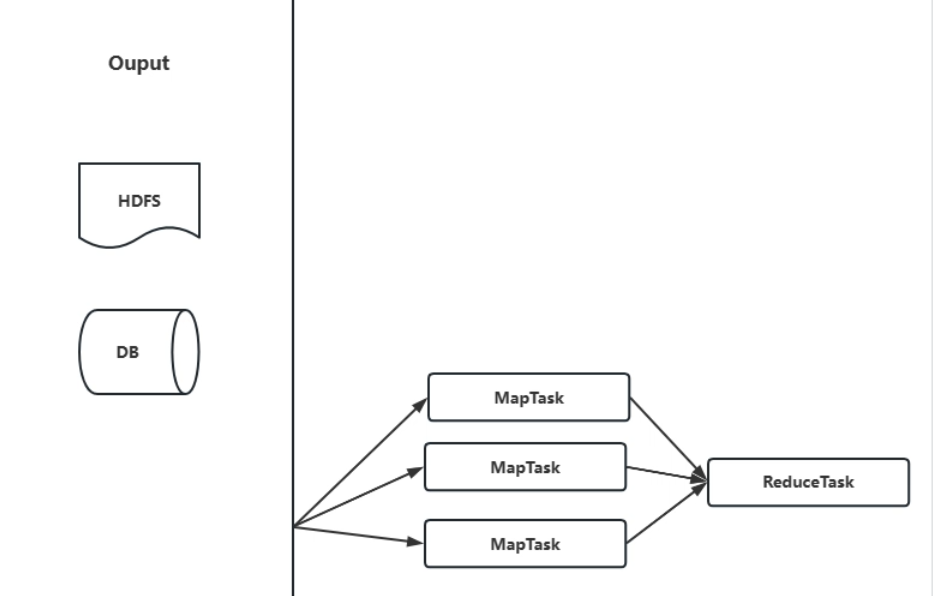
8.写出
- 完成所有操作并过完reduce代码后得到的数据可以存储到
- HDFS
- DataBase
- 如果得到的数据还不是最终数据还可以继续走一个MR。
4.Shuffle
可以简单理解为:Shuffle 是把 Map 的输出数据搬运并分配给 Reduce,使得相同键的数据都汇聚到同一个 Reduce 任务上。
-
数据传输:Map 任务把数据传给相应的 Reduce 任务。
-
数据排序和合并:保证数据有序地输入到 Reduce 任务中,方便 Reduce 进行最终的汇总、统计等操作。
Shuffle 阶段是为了让 Map 和 Reduce 有条理地连接起来,把分散的数据整合到一起,为最终计算做好准备。
5.MapReduce压缩
1.优点
- 压缩可以有效减少储存系统读写的字节数,提高网络带宽和磁盘空间效率。
- 改善磁盘I/O和网络I/O
2.缺点
- 压缩算法需要占用CPU算力
- cpu性能不够再使用压缩会负优化
3.使用压缩的条件
- 空间与CPU要充足
- 压缩的技术
- 有损压缩:压缩和解压过程中有数据丢失(音频/视频)
- 无损压缩:压缩和解压过程中没有数据丢失(日志数据)
- 对称压缩和非对称压缩
- 对称:压缩和解压时间一致
- 非对称:压缩和解压时间不一致
4.基本原则
- 计算密集型作业,少用压缩
- 特点:会因为大量计算占用CPU资源
- 因为主要使用CPU资源完成作业所以应当降低对CPU的占用。
- 所以应该尽量减少压缩占用CPU
- IO密集型作业多使用压缩
- CPU消耗少,大部分时间在等待I/O操作完成
- 因为这类任务99%的时间的都花在了I/O操作上,CPU占用低
- 所以应当使用压缩提高I/O效率
5.压缩支持
-
使用
hadoop checknative命令可以显示支持的压缩算法,如果显示支持为false就需要额外安装。压缩格式 算法 文件扩展名 是否可切分 压缩比 压缩速度 解压速度 DEFLATE DEFLATE .deflate F 高 低 低 Gzip Gzip .gz F 高 低 低 BZip2 BZip2 .bz2 T 高 低 低 LZO LZO .lzo T 低 高 高 LZ4 LZ4 .lz4 F 低 高 高 Snappy Snappy .snappy F 低 高 高 Zstd Zstd .zst F 高 高 高
6.使用压缩
-
要在Hadoop中启用压缩需要配置下面的文件与参数
-
core-site.xml
<!-- 可用于压缩/解压缩的编解码器,用逗号分隔列表 -->
<property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.BZip2Codec,
com.hadoop.compression.lzo.LzopCodec,
org.apache.hadoop.io.compress.Lz4Codec,
org.apache.hadoop.io.compress.SnappyCodec,
org.apache.hadoop.io.compress.ZStandardCodec
</value>
</property>
mapred-site.xml
<!-- 开启 Mapper 输出压缩 -->
<property>
<name>mapreduce.map.output.compress</name>
<value>true</value>
</property>
<!-- 设置 Mapper 输出压缩的压缩方式 -->
<property>
<name>mapreduce.map.output.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
<!-- 开启 Reducer 输出压缩 -->
<property>
<name>mapreduce.output.fileoutputformat.compress</name>
<value>true</value>
</property>
<!-- 设置 Reducer 输出压缩的压缩方式 -->
<property>
<name>mapreduce.output.fileoutputformat.compress.codec</name>
<value>org.apache.hadoop.io.compress.BZip2Codec</value>
</property>
<!-- 设置 SequenceFiles 输出的压缩类型:NONE、RECORD 或 BLOCK -->
<!-- 如果作业输出被压缩为 SequenceFiles,该属性用来控制使用的压缩格式。
默认为 RECORD,即针对每条记录进行压缩。
如果将其改为 BLOCK,将针对一组记录进行压缩,这是推荐的压缩策略,因为它的压缩效率更高。 -->
<property>
<name>mapreduce.output.fileoutputformat.compress.type</name>
<value>BLOCK</value>
</property>
- 除了使用配置文件的方式指定压缩,还可以使用代码来指定压缩
// 加载配置文件
Configuration configuration = new Configuration(true);
// 开启 Mapper 输出压缩
configuration.setBoolean(Job.MAP_OUTPUT_COMPRESS, true);
configuration.setClass(Job.MAP_OUTPUT_COMPRESS_CODEC, SnappyCodec.class, CompressionCodec.class);
// 创建作业
Job job = Job.getInstance(configuration);
// ... Job 的其他设置
// 开启 Reducer 输出压缩
FileOutputFormat.setCompressOutput(job, true);
FileOutputFormat.setOutputCompressorClass(job, BZip2Codec.class);
// 将作业提交到集群并等待完成
job.waitForCompletion(true);
6.MapReduce优化
1.小文件优化
- 小文件过多会导致元数据量过大,对NameNode造成压力。
- 小文件过多会增加磁盘寻址次数造成性能降低。
- 会导致MapTask启动时间过长,甚至大于计算时间。
- 可以在上传HDFS之前将小文件合成一个大文件
- 文件合成之后过大可以采用压缩(前提压缩必须是可拆分的格式)
- 尽量避免上传小文件。
2.数据倾斜
- 数据倾斜,每个 Reduce 处理的数据量大小不一致,导致有些已经跑完了,有些还在执行
- 还有可能就是某些作业所在的 NodeManager 有问题或者 Container 有问题或者 JVM GC 等,导致作业执行缓慢
- 原因,如数据本身就不平衡,所以在默认的 HashPartition 时造成分区数据不一致问题,还有就是代码设计不合理等。
- 不使用默认的 Hash 分区算法,采用自定义分区,结合业务特点,使得每个分区数据基本平衡;
- 或者既然有默认的分区算法,那么我们可以修改分区的键,让其符合 Hash 分区,并且使得最后的分区平衡,比如在 Key 前加随机数或盐 n-key
- 既然 Reduce 处理慢,那么可以增加 Reduce 的 memory 和 vcore,提高性能解决问题,虽然没从根本上解决问题,但是还有效果的
- 如果是因为只有一个 Reduce 导致作业很慢,可以增加 Reduce 的数量来分摊压力,然后再来一个作业实现最终聚合
