
Hadoop-HDFS

1.大数据思维
分而治之:把一个复杂的算法问题按照一定的方法分解,将方法分解为规模较小的若干部分,再逐个找出各部分的解,再把各部分的解组成整个问题的解,这就是分而治之
比如将一个大文件拆为多个小文件进行处理,计算,最后将这个文件按照索引组装。
2.分布式文件系统架构
- 元数据:元数据是数据的数据(记录数据的信息)
- NameNode:用于保存元数据(与DataNode对应)–主备
- DataNode:用于保存数据(与NameNode对应)–集群
1.基础架构(不分段正常上传)
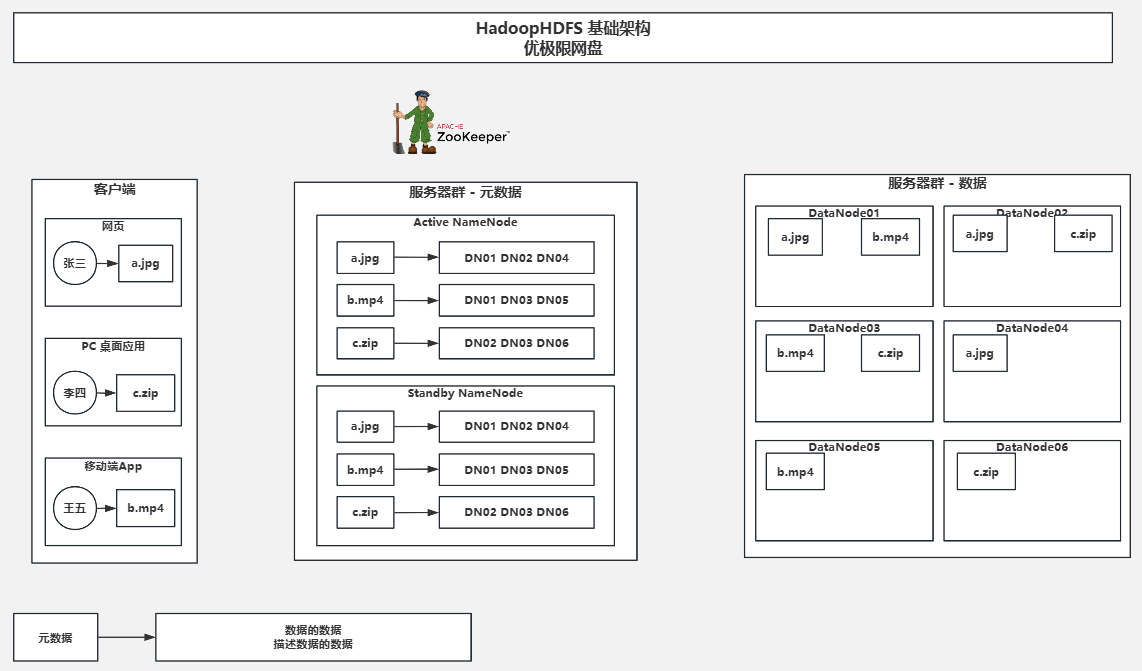
不分段上传,直接上传到DataNode集群并在NameNode中记录文件存储到集群中的那些节点。
2.进阶架构(分段上传)
- 因为数据底层都是字节数组,所以可以将数据分段,并通过数组索引再拼接。
- 数据分段之后可以多线程快速上传/下载。
- 客户端上传文件时,会对文件大小检查,超过默认阈值128M,会对其进行分段。
- 注意观察图中NameNode与DataNode的对应关系,以及与块(block的对应关系) 。
- 类似于DNS客户端先询问NameNode,获得存储数据在那些DataNode的信息,然后后客户端直接去连接DataNode进行,上传/下载。(避免经过NameNode造成带宽的浪费)
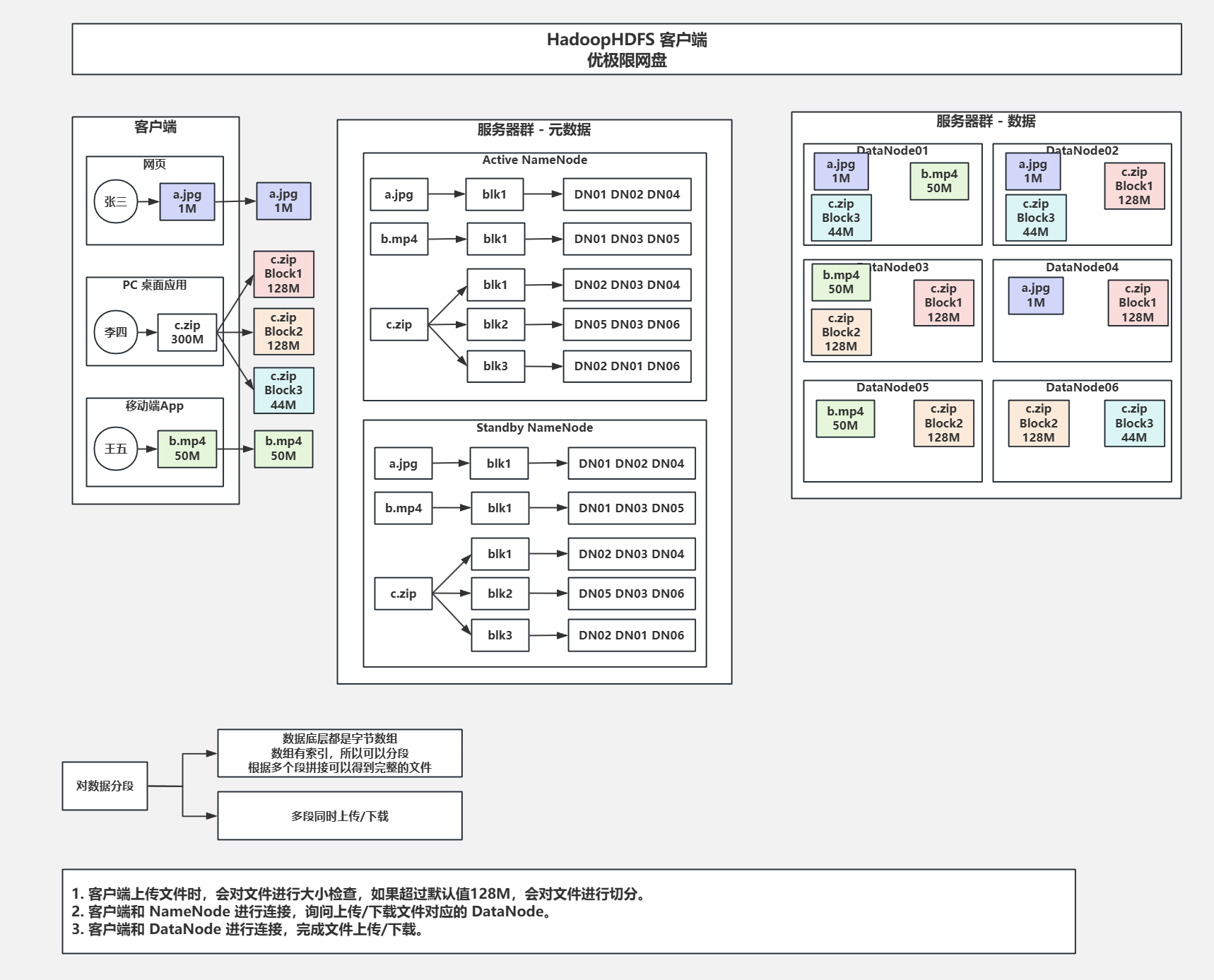
分段上传并在NameNode中记录元数据,客户端访问时直接与DataNode交互(上传/下载)
3.NameNode详解&QJM
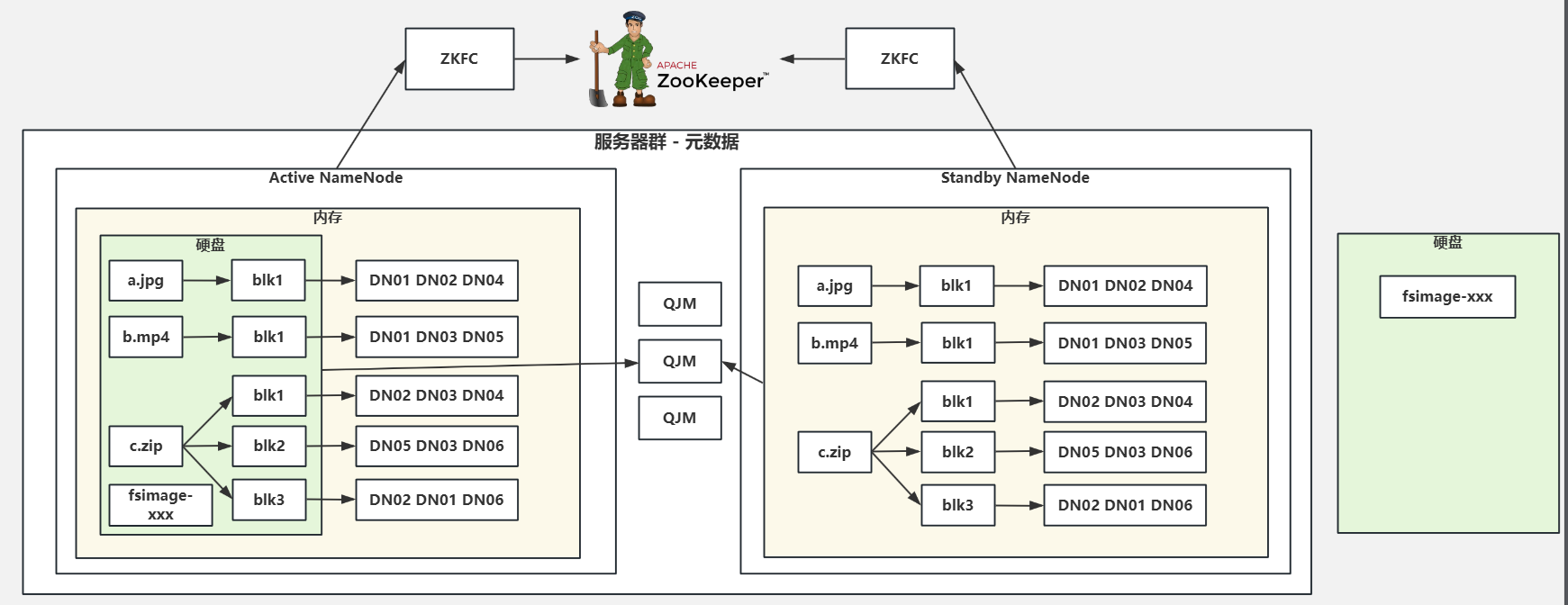
-
通过ZooKeeper选出主备服务
-
NameNode通过ZKFC(ZooKeeper故障转移控制器)实现主备切换。
-
当主节点宕机的时候会通过ZKFC(负责监听以及注册),当监听到宕机后备用节点的ZKFC会注册。
-
客户端上传/下载文件时,NameNode会将元数据存储至内存方便快速调用,同时也会将元数据存储至硬盘,防止元数据丢失。
-
元数据包含
- 文件名称
- 文件所属者
- 文件块信息
- 文件所处位置(DataNode节点信息)
- 权限信息
-
内存:文件名称,文件所属者,块信息,文件所处位置(DataNode节点信息),权限信息
-
硬盘:文件名称,文件所属者,块信息,权限信息
- 元数据在硬盘是如何存储的?
-
为了不丢数据,有一个文件叫做 edits-inprogress 存储的是内存中时时刻刻写入的元数据信息
-
每2min将 edits-inprogress 元数据滚动存储至硬盘,也就是说硬盘每2min会生成一个文件,文件名叫 edits-xxxxxxx,x 代表元数据事务次数
-
- 元数据在硬盘是如何存储的?
-
-
集群重启元数据信息来源:
-
将硬盘中的信息先读取到内存
-
DataNode会通过三秒一次的心跳将节点块信息与节点资源信息上报到NameNode获得文件所处位置(DataNode节点信息)。
-
Standby NameNode 会将 edits 文件进行合并与压缩,并将合并压缩后的文件通知 Active NameNode 验证并拉取,该文件叫 fsimage-xxxxxx
a. 时间阈值:默认1小时一次
b. 次数阈值:默认100W一次
a 和 b 工作线程的检查周期:默认1分钟一次
-
-
如何完整恢复元数据
-
读取 fsimage-xxxx 文件的元数据至内存,假设 xxx 是 150
-
读取大于 fsimage-xxxx 部分的 edits 文件,假设 edits-00000173 edits-00000246 …
-
edits-inprogress 文件的元数据至内存
-
-
NameNode 的选主是通过 ZKFC(Java程序) 和 ZooKeeper 完成选主与主备切换工作
为了保证元数据的绝对不丢失,我们会将硬盘中的元数据额外保存至第三方,叫做 QJM -
只有 Active NamoNode 才会生成硬盘的 edits 文件,Standby NameNode 只是合并 edits 文件为 fsimage,所以 Standby 硬盘只会有 fsimage 文件。但是当 Active NameNode 宕机时,Standby 会升级为 Active,此时它硬盘也会开始生成 edits 文件。总结,两个 NameNode 上所有的 edits(xxx 和 inprogress) 文件才是最完整的元数据信息。
-
Standby NameNode 内存中的元数据是如何同步过来的?
Standby NamoNode 会通过 QJM 读取元数据并写入内存,当 Active NamoNode 宕机时, Standby 就可以马上顶替工作。
-
为了保证元数据的绝对不丢失,我们会将硬盘中的元数据额外保存至第三方,叫做 QJM
QJM 是一个小型分布式文件存储系统,QJM 如何是高可用,怎么解决数据一致性问题?所以 QJM 内部也实现了 Paxos 算法。
Standby NamoNode 会通过 QJM 读取元数据并写入内存**(Active NameNode在将数据写入内存和硬盘的时候也会将数据写入QJM防止元数据丢失)**,当 Active NamoNode 宕机时,Standby 就可以马上顶替工作。
4.DataNode详解
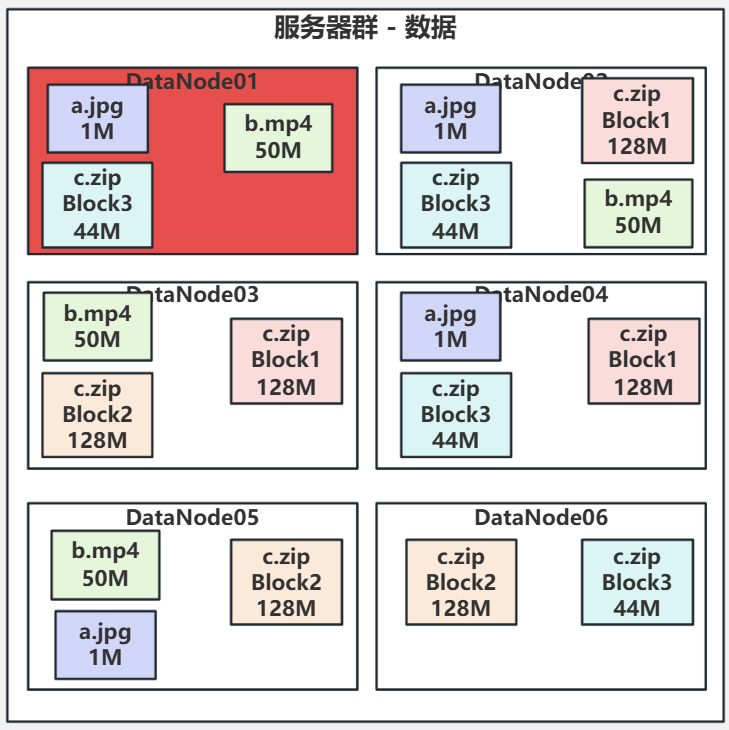
节点宕机
- 客户端与DataNode连接完成文件的上传下载
- DataNode会通过三秒一次的心跳将节点块信息与节点资源信息上报到NameNode内容为文件所处位置(DataNode节点信息)。
- DataNode可能宕机,其他DataNode节点会通过NameNode的命令进行文件的拷贝,拷贝到集群最小副本数(默认为三份)。
- 下图红色表示节点已经宕机,并且通过三秒心跳补全了最小副本数。
客户端文件上传&下载
-
上传:客户端通过管道(pipline)连接一台DataNode节点,剩下的其他几个节点与客户端连接的节点也使用管道连接将数据拷贝过去。(ack为响应也是逐级响应以此类推)
-
下载:下载可以多DataNode同时下载,字节数组可以根据字节数组的索引进行拼接。

补充
- 客户端询问文件上传位置时,Act NameNode是通过机架感知策略(可以理解为网络状况最好的包括距离最近的服务器)以及DateNode资源来反馈给客户端的。
- 下载时Act NameNode会通过网络拓扑图来对节点排序。
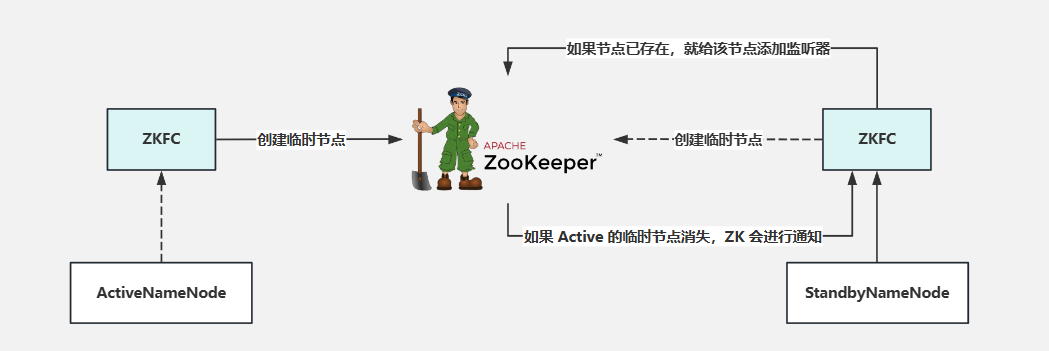
5.ZKFC&ZooKeeper&脑裂问题
-
Act NameNode与Stan NameNode 是服务器所以连接到Zookeeper需要客户端,客户端就是ZKFC这个java类,当选主开始时会创建一个临时节点,谁先创建谁就是主。
-
ZKFC会在节点存在之后为该节点添加监听器。

-
脑裂问题
-
如果出现网络波动导致原主节点假死在恢复时集群会出现两个主节点
-
此时ZKFC会通过ZooKeeper尝试对原主节点降级处理。
-
如果原主节点因为部分原因导致不回复降级,则会kill掉该进程。
-
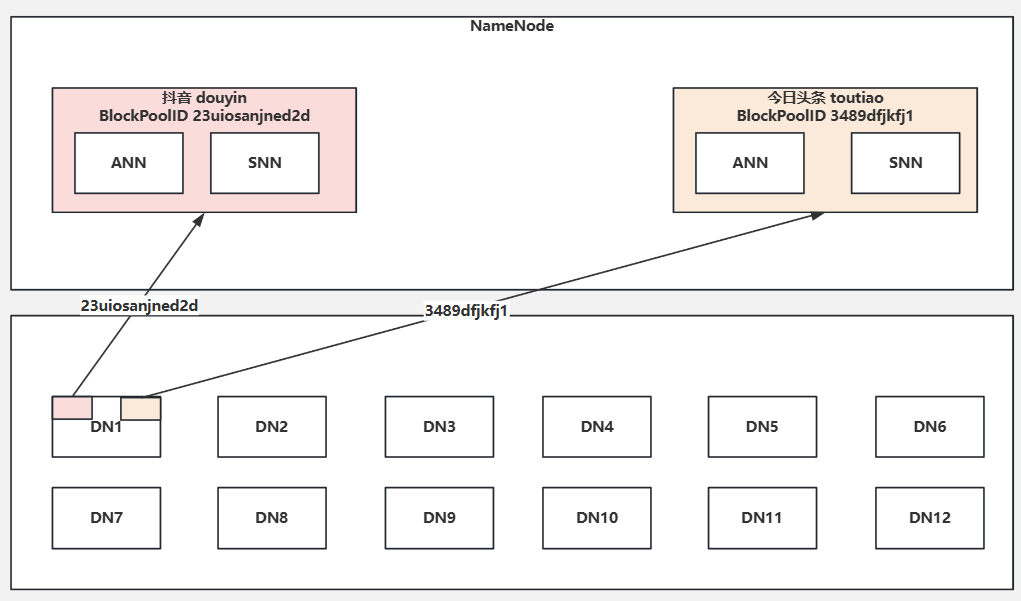
3.联邦机制
- DataNode(DN)
- Active NameNode (ANN)
- Standby NameNode(SNN)
- 在传统的 Hadoop 架构中,HDFS 使用单个 NameNode 来管理整个集群的文件系统命名空间和元数据
- 扩展性受限:单个 NameNode 的内存和处理能力有限,无法管理大量的文件和目录。
- 可靠性风险:单 NameNode 架构会产生单点故障,一旦 NameNode 失效,整个 HDFS 文件系统就不可用,尽管在 Hadoop 2.x 引入了 HA(高可用)机制,但仍无法解决扩展性问题。
联邦机制架构
- 多个 NameNode(命名空间服务器):每个 NameNode 管理一个独立的命名空间,包括文件、目录及其元数据。NameNode 间彼此独立,互不通信,因此每个 NameNode 只需维护自己负责的部分。
- DataNode(数据节点):DataNode 负责存储数据块。DataNode 会向所有 NameNode 注册,并能存储来自多个 NameNode 的数据块。
- 块池(Block Pool):每个 NameNode 对应一个独立的数据块池(Block Pool),这些块池分别管理各自的元数据和数据块。在写入数据时,不同 NameNode 的数据块不会互相影响。
工作原理
- 命名空间隔离:每个 NameNode 只管理特定的命名空间,客户端通过指定的 NameNode 访问其命名空间下的文件和目录,这样可以有效分散 NameNode 的负载,避免单点过载。
- 数据块池隔离:DataNode 既能存储多个命名空间下的数据块,同时又将不同命名空间的数据块彼此隔离开,确保数据安全和独立性。这种隔离方式允许不同 NameNode 管理的文件系统具有各自的数据块池。
- DataNode 与 NameNode 分离:DataNode 作为共享资源,无需关心数据属于哪个命名空间,仅负责存储和管理数据块,从而使得数据节点的存储利用率更高。




That’s a solid point about responsible gaming – platforms like jl29 slot download making verification easy (KYC) is a smart move for both players & themselves. Seamless payments via GCash are a huge plus too! 👍
Really interesting read! The focus on data-driven play is smart – seeing stats while you play could be a game-changer. Thinking of checking out 588jl apk to see how that works in practice for mobile gaming! Great insights here.