Zookeeper
ZooKeeper 是 Apache 软件基金会的一个软件项目,它是一个为分布式应用提供一致性服务的软件

1. 集群与分布式
1.集群:
集群将多台服务器用于同一个任务保证可用性。
2.分布式:
分布式将一个任务的不同模块分开部署到不同的服务器降低耦合。
2. CAP原则与BASE理论
| 特性 | 定理 |
|---|---|
| Consistenc | 一致性,在分布式系统中更新执行成功后所有的节点都应该读取最新的值这就叫做一致性。 |
| Availability | 可用性,每个操作都能在一定的时间范围内返回结果结果可以是成功也可以是失败,且不保证获取的数据为最新。 |
| Partitiontolerance | 分区容错性,分布式系统在部分服务器故障时候仍能保证一定的一致性和可用性,性能可弹性伸缩 |
1.取舍策略CAP原则
CAP三个特性只能满足其中两个所有取舍策略就只有三种
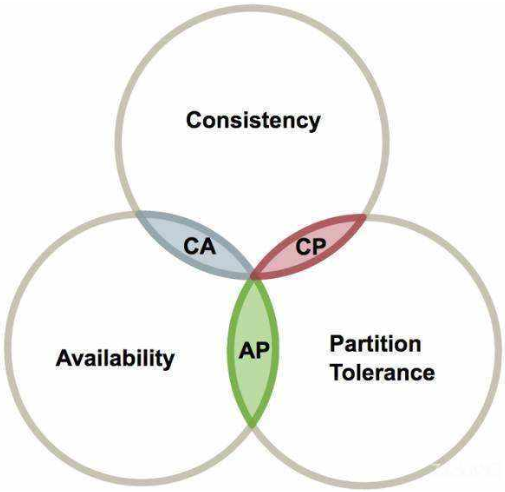
1.CA
强一致性和高可用,牺牲了系统的扩展性没办法部署子节点。
2.CP
牺牲可用性,需要等到全部数据同步之后才有返回
3.AP
会导致系统全局数据不一致,一旦产生分区节点之间可能会出现问题
CAP 原则指出分布式系统中只能选择一致性、可用性和分区容错性中的两个特性。
3.BASE理论
为了曲线救国解决cap原则的问题提出了base理论
BASE:全称 Basically Available(基本可用),Soft state(软状态),和 Eventually consistent(最终一致性)三个短语的缩写,来自ebay 的架构师提出。
1.基本可用
系统在网络分区或部分节点故障的情况下仍然能够提供服务,但可能会有延迟或功能降级。
2.软状态
分布式系统允许部分节点存在一段时间的数据不同步状态,而不要求严格的一致性。
3.最终状态
系统在没有更新的情况下,经过一段时间后,所有节点的数据会最终达到一致。
牺牲强一致性来满足可用性,允许数据在一定时间内是不一致的,这就是BASE理论
3.数据的一致性
1.强一致性
强一致性保证每次读取的都是最新的数据。即使在网络分区或系统故障的情况下,也不会返回旧数据。所有数据更新后,任何节点都能立刻看到最新的数据。
2.弱一致性
弱一致性允许读取到旧数据,数据不会强制要求在所有节点之间即时同步更新。更新后的数据可能会在一段时间后才被其他节点看到,也可能出现一致性差异。
3.最终一致性
是弱一致性的一种特例,保证用户最终能够读取到某操作对系统特定数据的更新。
4.Paxos算法
Paxos算法是Leslie Lamport宗师提出的一种基于消息传递的分布式一致性算法。

1.核心思想
Paxos 是一种基于消息传递的分布式一致性算法,适用于不可靠的网络环境。它通过多次通信,确保所有节点对一个值达成一致。Paxos 的核心思想可以概括为“三阶段投票”:
1.Prepare 阶段(准备)
提议者向接受者发起请求,表明自己打算提议一个值,询问是否可以接受提议。
2.Promise 阶段(同意)
接受者收到请求后,若同意该提议,则承诺不再接受编号小于该提议编号的其他提议。
3.Accept 阶段(接受)
提议者在收到大多数节点的承诺后,向这些节点发送接受请求;如果大多数节点接受了该值,则认为该值已被决议。
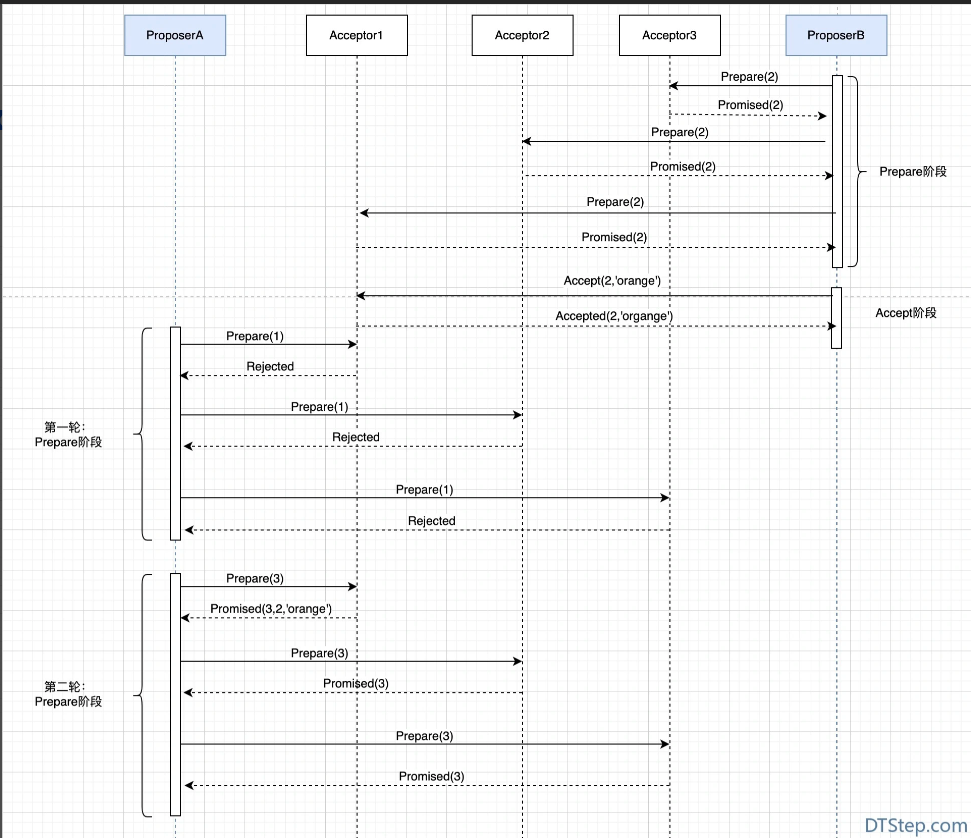
2.流程
-
a、ProposerA 发起 prepare(1)的请求,由于该编号小于提案编号 2,所以请求被拒绝;
-
b、ProposerA 发起 prepare(3)的请求,该编号大于编号 2,则被接受,Accetpor1 返回 Promised(3,2,’orange’),表示接受编号 3 的提案请求,并将之前接受过的最大编号提案和提案值返回。
-
c、Acceptor2 和 Acceptor3 均返回 Promised(3),表示接受编号 3 的提案请求。
3.Paxos算法选主
1.初次选主
-
无脑选编号最大的为主——快速选主
-
加入投票机制,票数过半才可以成为主
-
投票默认投给编号最大的
-
每次选主成功都会有朝代标记
2.主宕机重新选主
- 先过滤出与公共pid相同的节点
- 再与初次选主一样进行选主
- 选出主之后其他节点要与该节点进行数据同步
4.角色
- 领导者:主节点(所有提议的发起者接受客户端写请求数据更改等)
- 跟随者:投票响应提议(转发客户端写请求给领导者)
- 观察者:只转发客户端写请求到主节点不参与投票提议(只给客户端提供读请求)
5.ZAB协议
1.zab协议有三个阶段
【发现,同步,广播】
1.发现
集群必须选出一个“主”leader(选主),同时leader会维护一个follower可用列表,客户端可以与其通信。
2.同步
leader要负责将本身的数据与follower完成同步,做到多副本存储。这样也是体现了CAP中CP。follower将队列中未处理完的请求消费完成后,写入本地事物日志中。
3.广播
leader可以接受客户端新的proposal请求,将新的proposal请求广播给所有的follower。
2.协议内容
1.崩溃恢复
- 如果集群发生网络波动,导致原“主”离线,ZAB协议会进入恢复模式产生新“主”,且集群中有一半follower完成数据同步后ZAB协议会退出恢复模式
- 当所有节点完成数据同步之后整个集群会进入消息广播模式,在leader节点正常工作时有新的服务器加入时,这台服务器会进入恢复模式,同步数据完成后可正常对外提供服务。
- 在消息广播中每一个事物都会被leader转换成对应的proposal来广播,并且在广播开始前会为其分配一个全局的单递增的id就是zxid,因为zab协议会保持事物的执行顺序,会严格按照zxid来决定执行的先后。
2. 消息广播
- zookeeper集群数据副本同步与二段提交相似但是有不同,二阶段提交要求全部参与者全部返回ack确认消息,会造成堵塞,但是zookeeper的数据同步是需要一半的参与者返回ack确认消息即可完成同步,不需要收到全部的ack返回确认消息。
3. ZAB 协议的容错性
- Leader 故障:当 Leader 节点发生故障或出现网络分区时,集群会进入崩溃恢复模式,重新选举新的 Leader 并同步数据,以确保系统可以继续处理请求。
- 网络分区:ZAB 协议要求大多数节点存活以保证系统的正常工作。如果由于网络分区导致的节点数少于集群总数的一半,集群将暂停服务,等待网络恢复。
6. Raft算法
角色
leader:主节点(所有提议的发起者接受客户端写请求数据更改等)
follower:投票响应提议(转发客户端写请求给领导者)
candidate:候选人,在选主阶段前期的角色(临时)
选主(与paxos算法的选主过程不同)
-
所有节点都是从跟随者开始
-
选举超时150ms – 200ms在选举超时后该节点成为候选人选举任期
-
候选者为自己投票,并请求其他节点为他投票
-
接受到请求的节点会重置自己的选举超时时间
-
当候选人获得过半票数就会成为候选人
-
并且在任期时“主节点”会一直向其他节点发送心跳,直到宕机
-
如果“主”发生宕机,那么剩下的节点因为收不到append追加条目就会选举超时,开始新的的选主和任期。
-
如果集群中同时出现两“主”会重新开始选举到下一个任期




